When maintaining a Hadoop cluster, you will need to restart various service from time-to-time when/if you update Hadoop configurations.
I ran into a problem today with Ambari where I wanted to do a rollling restart of all of my DataNodes, but when I clicked on the “Restart DataNodes” entry in the “Restart” drop down the dialog indicated “There are no DataNodes to do rolling restarts”.
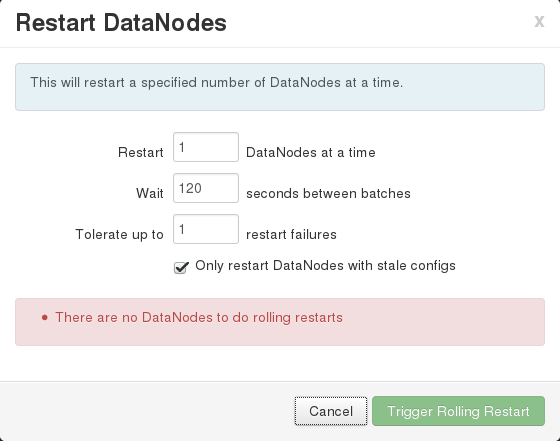
This was clearly incorrect.
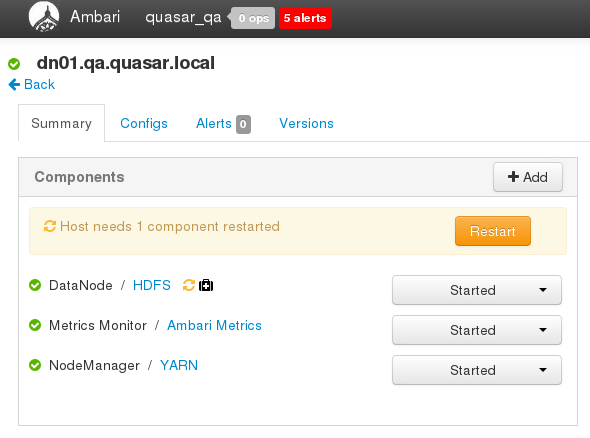
It did not take me too long to figure out that → Continue reading “[SOLVED] Ambari There are no DataNodes to do rolling restarts when there are DataNodes that do need a restart”